My tool-kit for tiny long-run batch jobs
In my first story in this series, I explained that I spend about a day a week solving problems that interest me with tiny software applications. I’ve been assembling a tool-kit to quickly build against architectural patterns that I find keep coming up in tiny apps. The technology I choose has to solve these problems:
- I only want to pay for what I use (scale-to-zero)
- I don’t have a lot of time available for learning or building (no steep learning curves without substantial time-savings)
- I don’t have time for maintenance activities (no patching servers, automated scale-up)
- I’m not a good UI designer or front end engineer (design systems are great)
In my fourth story in the series, I explained my approach to doing background processing that isn’t in response to an interaction from a user interface, where the processing will complete in a minute or less. AWS Lambda works well in that situation, but Lambda isn’t so great when a job is going to run for a long time. The costs start creeping up, and the global maximum execution time has a maximum allowed duration of fifteen minutes. Fortunately AWS also provide AWS Batch, which is ideal for longer running jobs, but is a bit more complicated than deploying a Lambda.
To illustrate this tool-kit I’ll use a different side-project example: web-scraping Goodreads and the book catalogues at my local libraries.
TL;DR
- AWS Batch with AWS Elastic Container Service (ECS) and AWS Elastic Container Registry (ECR)
- Docker with Node.js on AWS EC2
- AWS S3
- AWS EventBridge (formerly the “events” part of CloudWatch)
- Github Actions
The business problem
I do all my reading on e-books and e-audiobooks. I read mostly literary fiction, and libraries here in New Zealand provide an excellent service via Overdrive, BorrowBox, and Ulverscroft. I’m a big Goodreads user, and I get as frustrated as everyone else with the poor and deteriorating user experience, removal of APIs, and general stagnation of what was once long ago an independent, cutting-edge way to manage bookmark lists and reviews. But… Goodreads have all the data.
Every time I finish a book and want to borrow a new one, the basic question I want to answer is “what books that I might want to read are available in digital format at my local library?”. This is tricky because:
- Goodreads doesn’t have an API (its owner, Amazon, shut it down 👿)
- The library catalogues don’t have public APIs
I like to read books that win literary awards or appear on Goodreads user-curated lists, so what I want to do is take all of the books on the lists of award winners and useful community lists (Goodreads has lists of award winners), and see which ones are available in digital format at my local library. I also want to check if any of the books I have shelved in my “to-read” shelf on Goodreads are available.
Without APIs, I need to employ web-scraping techniques to visit and analyse the data. Web-scraping is slow and book lists are long, so I need to do this in a long-running batch job.
The application I built to use this data (only available for Auckland and Wellington libraries in New Zealand, sorry) is “What Can I Borrow?”. I used the same tool-kit as I described in my second story in this series.

The basic process
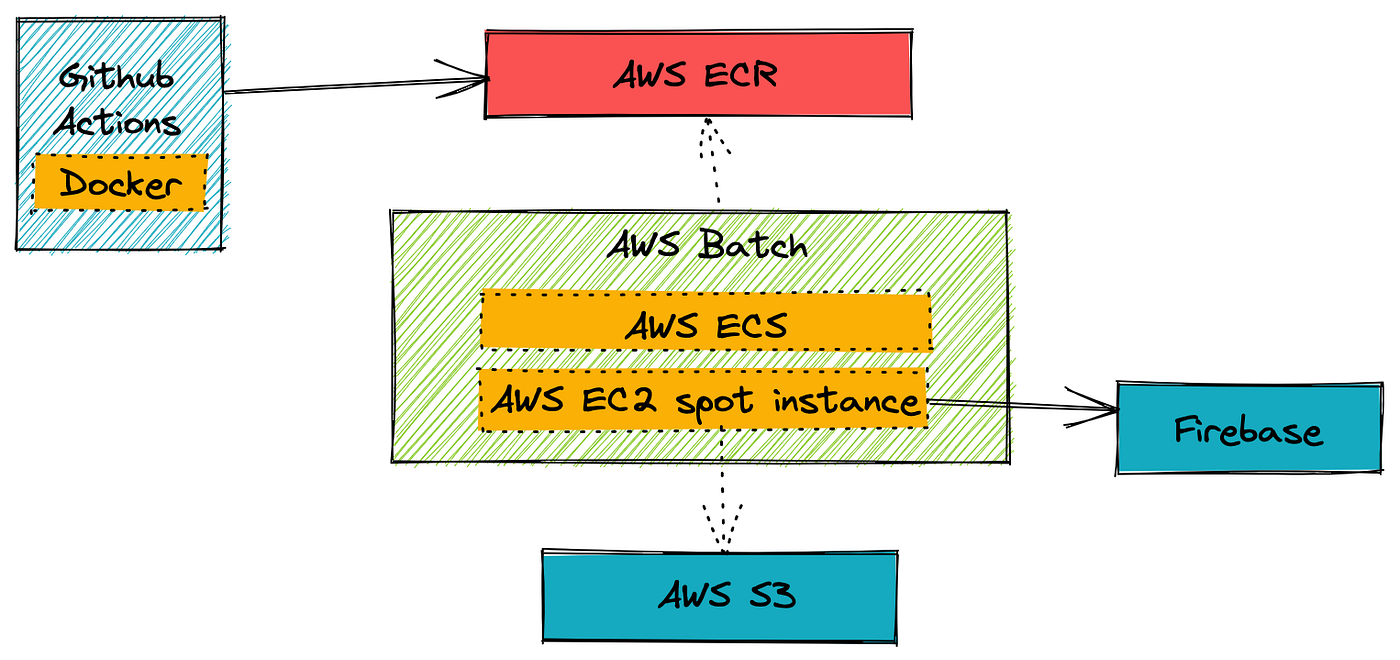
In my solution, a scheduled event in AWS EventBridge runs a job in AWS Batch once a week. The job is a Docker container with Node.js code in it that grabs a definition file from S3 containing the URLs of the Goodreads list or shelf to visit. For each list or shelf, it extracts the metadata for the books, searches for each one in the library catalogues, and stores the matches in a Firebase database for the app to use later.
As I noted in my last story, while I won’t go into the details of how I do scraping here, I use SuperAgent with Cheerio. Cheerio has excellent support for CSS selectors on full HTML docs and snippets, and I find that sticking to CSS selectors makes for much easier to maintain scraping code.
Three problems to solve
My tool-kit needs to solve the first three of the problems I’ve mentioned:
- I only want to pay for what I use (scale-to-zero)
- I don’t have a lot of time available for learning or building (no steep learning curves without substantial time-savings)
- I don’t have time for maintenance activities (no patching servers, automated scale-up)
The execution environment
AWS Batch works by spinning up Docker containers on either the AWS Fargate grid or EC2 spot instances and running them until they complete execution. Batch provides parameters for setting resource usage restrictions to make sure jobs don’t spin out of control and rack up charges. The basic data model is that a “job” is an instance of a “job definition”, which is managed in a “job queue”, and runs in a “compute environment”. The resources are configured in the compute environment, the queue is either Fargate or spot, and the job definitions have more detailed resource control and can contain parameters and environment variables.
The container
Under my “no steep learning curves without substantial time-savings” principle, I’m yet again appreciating that I can write my code in the language and platform I am most familiar with: Node.js. I haven’t used Docker much because most of the time for tiny apps, YAGNI. It was worth doing the local installation and troubleshooting for this use case though because the Batch system saves me a huge amount of time that could be spent inventing some kind of background processing architecture for long running jobs that can still use Lambda.
The Dockerfile I ended up with is very simple:
FROM node:latest
WORKDIR /usr/src/app
COPY lib lib
COPY populatefirestore.js .
COPY package.json .
COPY firebaseconfig.json .
RUN npm install
ENTRYPOINT [ "node", "populatefirestore.js", "-e"]I’m using the official Node Docker image, which will run my populatefirestore.js script and pass it the “-e” parameter. This parameter tells the script to read its config from environment variables, which I set in the job definition in Batch.
The repo
AWS ECR is a Docker container repository. I created a private repository in my AWS account. The console for ECR provides an easy to use copy-and-paste of the necessary AWS and Docker CLI commands to run locally to log into the repository, build and tag the image, and push it.
The job execution
The job definition in AWS Batch is very simple. The image in ECR is referenced with a URL containing my AWS account ID, repo ID, and the Docker tag. The command is set to ["docker","run","<repoid>:<tag>"]. The only additional configuration I add is an environment variable for my script to read so it knows which Goodreads list definition to read from S3.
I did strike a gotcha with configuring access to an S3 bucket for my Batch job. There are two IAM roles on a Batch job definition: “execution role” and “job role”. The execution role is only used by Batch to fetch and start the container, but the optional job role is used by the running container for everything else. Therefore, it’s the “job role” that needs to have access to the S3 bucket and be set on the job definition.
AWS EventBridge has built-in support for AWS Batch jobs, so it is straightforward to hook up a scheduled rule to a job.
Deployment
Unlike my short-run batch jobs, I haven’t automated the deployment of the Batch configuration and EventBridge rules, but these rarely need to change. Next time something crops up when I need this pattern again, I’ll use AWS CDK to automate it.
For the container build, it was Github Actions to the rescue again! A community action for logging into ECR was all I needed to run the Docker job automatically on any push.
name: Production build for populatefirestore in Docker container on ECRon:
push:
branches: [ master ]jobs:
deploy:
name: Deploy
runs-on: ubuntu-latest
steps:
- name: Checkout Repo
uses: actions/checkout@master- name: Write Firebase credentials from secret
env:
FIREBASE_CREDENTIALS: ${{secrets.FIREBASE_CREDENTIALS}}
run: 'echo "$FIREBASE_CREDENTIALS" > firebaseconfig.json'- name: Configure AWS credentials
uses: aws-actions/configure-aws-credentials@v1
with:
aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }}
aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }}
aws-region: ${{ secrets.AWS_REGION }}- name: Login to Amazon ECR
id: login-ecr
uses: aws-actions/amazon-ecr-login@v1- name: Build, tag, and push image to Amazon ECR
env:
ECR_REGISTRY: ${{ steps.login-ecr.outputs.registry }}
ECR_REPOSITORY: <myrepoid>
IMAGE_TAG: latest
run: |
docker build -t $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG .
docker push $ECR_REGISTRY/$ECR_REPOSITORY:$IMAGE_TAG
Summary
Let’s revisit those principles.
I only want to pay for what I use (scale-to-zero)
As with short-run jobs, the cost of the services here is totally under my control. I run four 10 minute jobs once a week, and in the full months of June, it cost 9c.
I don’t have a lot of time available for learning or building (no steep learning curves without substantial time-savings)
Using Node JS for my function code in AWS Batch meant no new languages to learn. It was worth learning a bit of Docker to take advantage of the Batch infrastructure.
I don’t have time for maintenance activities (no patching servers, automated scale-up)
The stack is serverless and will scale up as required. Github Actions automates deployment.
Bonza!
